AI Product Design · Co-founder · 2024–2025
Lumet.to — Designing for
LLM Brand Visibility
Role
Co-founder, Lead Product Designer — Brand System, Visual Identity, UX Design
Timeline
2025-2026
Tools
Figma, React, TypeScript
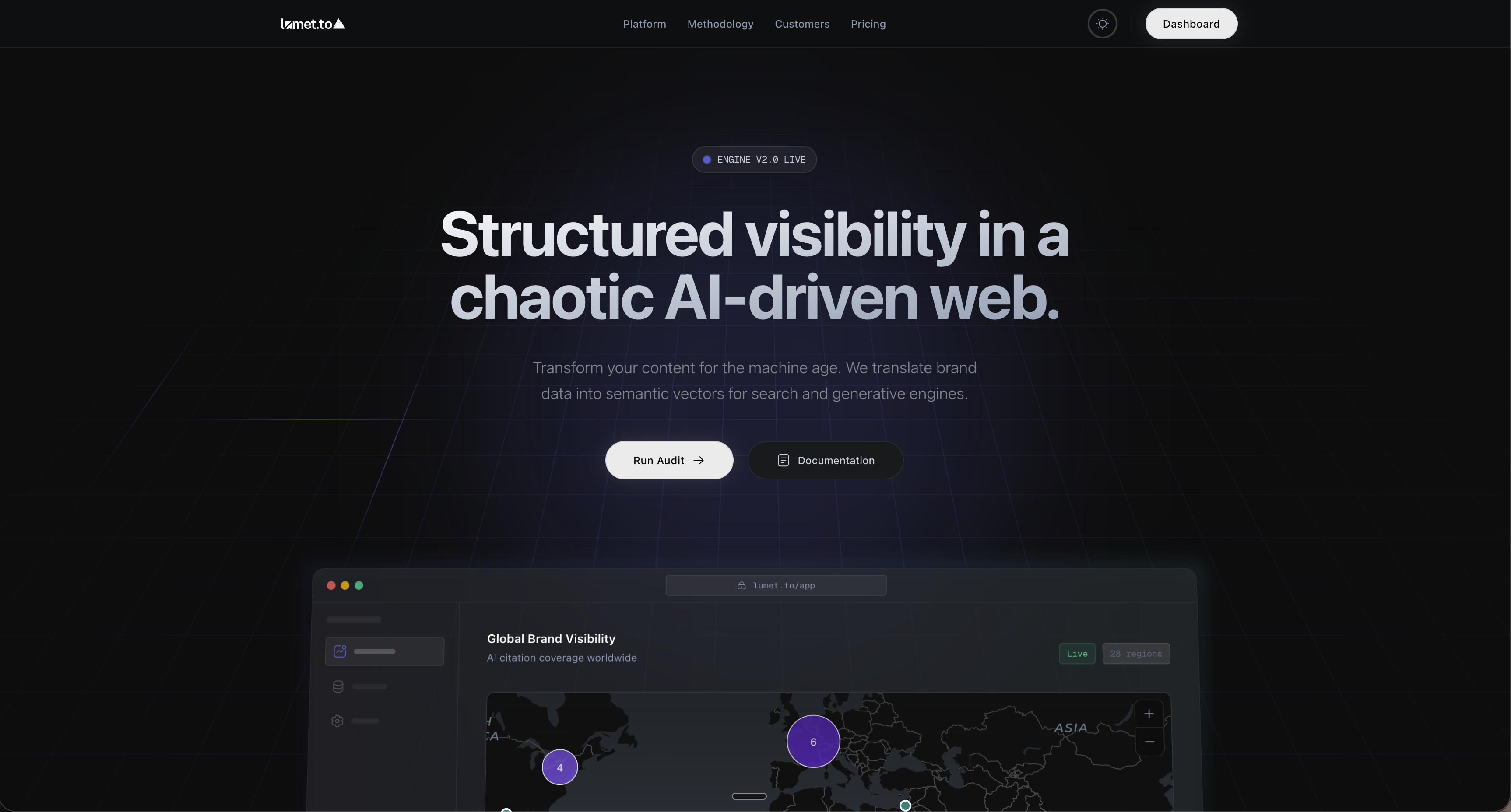
The hook
In 2025, while working at DG Cosmetics, I noticed something no dashboard was tracking: when a potential customer asked ChatGPT which skincare brands to try, our brand didn't appear. We had invested heavily in SEO. We ranked well on Google. But the new discovery layer — the one increasingly shaping purchase decisions — was invisible to us. We had no way to know if we existed inside AI systems, let alone how to improve our presence there.
That gap was the product.
Research
Autoethnographic discovery + stakeholder synthesis
My primary research method was autoethnography: I was the user experiencing the problem firsthand. Working inside a mid-size beauty brand gave me direct access to the question B2B marketing managers are now asking but have no tools to answer.
The core observation
SEO tools measure search engine presence. Social analytics measure social reach. But there was no category of tool measuring LLM presence — the layer where AI systems like ChatGPT, Claude, and Gemini form opinions about brands and surface them to millions of users daily.
What I documented from that experience:
Marketing teams don't know which LLMs mention their brand, in what context, or with what sentiment
There is no feedback loop between brand investment and LLM visibility
The prompt phrasing used to query an LLM dramatically changes whether a brand appears at all
Competitors could be dominating LLM responses while a brand remained completely unaware
Stakeholder conversations with my co-founder — who came from a technical AI background — helped me translate these observations into product requirements. Our synthesis produced one core insight:
"B2B marketing managers need to see their brand's LLM presence the same way they see their search ranking: as a measurable, actionable metric — not a mystery."
Research gap I'm addressing now: I'm currently planning a formal research study with 5–8 B2B marketing managers to validate these insights and deepen the case study. If you're a marketer dealing with this problem, I'd love to talk.
The user
Assumed persona — to be validated through research
Name
Maya, 34
Title
Brand Marketing Manager
Company
Mid-size DTC brand, $10M–$50M revenue
Goal
Prove marketing ROI to leadership; stay ahead of emerging channels
Frustration
"I can tell my CEO we rank #3 on Google. I have no idea what AI systems say about us."
Mental model
Thinks in dashboards, metrics, comparisons. Needs confidence, not uncertainty. Wants one number she can report upward.
The critical design tension
This persona was constructed from firsthand observation, not user interviews. The planned research study will validate or challenge these assumptions. LLM visibility data is inherently uncertain — outputs vary by prompt, by model, by day. Maya needs actionable clarity. The design had to make uncertainty legible without making it paralyzing.
AI design decisions
Where this gets interesting
This is the section most designers skip. Here's what I actually decided about the AI layer, not just the UI around it.
Decision 1
One score, with visible methodology
LLM visibility can't be reduced to a single clean number — but a B2B marketing manager needs something she can report to her CMO. I designed a composite visibility score (0–100) that aggregates brand mention frequency, sentiment, and model coverage. Crucially, the score is always accompanied by a "how this is calculated" tooltip. Transparency is built into the display, not hidden.
Why this matters as a design decision: I chose to show confidence rather than hide uncertainty. A score without methodology is a black box. A score with a visible calculation method is a design artifact that builds trust in the AI system.
Decision 2
Model disaggregation as a first-class view
Early thinking was to show one aggregate score across all LLMs. I pushed against this. ChatGPT, Claude, and Gemini have meaningfully different training data and update cadences — a brand visible in one may be invisible in another. I designed the LLM breakdown as a primary view, not a drill-down. This respects the actual complexity of the underlying data.
Framework reference: Google PAIR Guidebook — "Show model limitations clearly."
Decision 3
Prompt injection as a tool, not a hidden feature
The prompt injection tool — which helps brands optimize how they appear in LLM responses — could have been buried in settings. I surfaced it as a primary workflow because it's the only action a marketer can take to change their score. Visibility without actionability is just anxiety. The design creates a loop: measure → understand → act → measure again.
Decision 4
Avoiding false precision in trend data
Trend charts for LLM visibility are tricky — a dip might mean the model updated, a prompt changed, or the brand actually lost ground. I added contextual annotations on the trend line to flag model update events, separating signal from noise. This was directly informed by my experience at DG Cosmetics watching teams misread social analytics dips.
Design process
Brand → wireframes → live product
Starting point: the brand system. Before any screens, I established the visual language — because with a co-founder focused on backend/AI, design was entirely mine to own. Purple-dominant palette signaling intelligence and precision, clean typographic hierarchy, a neumorphic-influenced component style that felt premium without being decorative.
Wireframes → component system → live product. I worked in Figma for wireframes and component architecture, then built the frontend directly in React + TypeScript. The design system lives in code, not just in Figma.
Key iteration
The initial dashboard showed too much. An early version surfaced five metrics simultaneously — visibility score, model breakdown, prompt performance, competitor comparison, and trend data. In internal review with my co-founder, we recognized this was a power-user view, not a marketing manager's view. I reorganized around a single primary metric (the visibility score) with progressive disclosure into the supporting data. One number at the top. Everything else one click away.
Accessibility decisions: Color is never the only signal. Every status indicator (brand visible / not visible / partial) uses both color and a text label. Contrast ratios meet WCAG AA across the dashboard.
Outcome
The product is live
The core loop — measure LLM visibility, understand which models are surfacing your brand, act through prompt optimization — works end to end.
What I'm tracking going forward: do marketing managers return to the dashboard weekly (habit formation), and does the visibility score change meaningfully after prompt injection actions (product efficacy). These are the two metrics that will determine whether the product creates real value or just interesting data.
My specific contribution
Full design surface — end to end
I owned the entire design surface: brand identity, design system, component library, wireframes, and frontend implementation in React. My co-founder owns the AI/backend infrastructure — the LLM querying, data aggregation, and prompt injection engine.
The product design decisions described above — score display, model disaggregation, surfacing prompt injection as a primary workflow — were mine.
What I'd do differently
Research before building
I'd start with user research before building. The core insight came from lived experience, which gave us a real problem to solve — but I designed for a mental model of the user rather than an observed one. The marketing manager persona is grounded in my own experience, not in interviews.
That's the thing I'm fixing now: running the research study I should have done first, and using it to validate or challenge every assumption baked into the current design. If the interviews surface something that contradicts the dashboard architecture, I'll redesign. That's the process.